چیزی است که همه ما به صورت شهودی معنای آن را میفهمیم، اما در واقع تعریف آن به شکل رسمی ساده نیست. به طور کلی، موضوع، ایده اصلی است که در متن بحث شده است، که میتواند به عنوان زمینه یا مبحث یک متن یا سخن نیز تلقی شود. موضوع میتواند سطوح مختلفی داشته باشد. مثلا، میتوانیم درباره موضوع یک جمله، موضوع یک پاراگراف، موضوع یک مقاله یا موضوع تمام مقالات تحقیقاتی در یک کتابخانه صحبت کنیم که هر کدام از این سطوح کاربردهای خاص خود را دارند.
مباحث پیشرفته یادگیری عمیق؛ Graph Convolution Network (GCN)
کاربردهای فراوانی وجود دارد که لازمه آن کشف و تحلیل موضوعات متن است. مثلا، ممکن است بخواهیم بدانیم امروز کاربران توییتر در مورد چه چیزی صحبت میکنند؟ پیرامون لیگ جهانی والیبال، رخدادهای بینالمللی یا موضوعات دیگر؟ علاوه بر این ممکن است بخواهیم موضوعات تحقیقاتی را بشناسیم؛ ممکن است فردی بخواهد بداند که موضوعات تحقیقاتی جاری در دادهکاوی چه هستند و چه مقدار با موضوعات 5 سال قبل تقاوت دارند. برای پاسخگویی به این قبیل سوالات، باید موضوعات متون دادهکاوی را کشف کنیم که شامل موضوعات امروزی متون و موضوعات گذشته است و در نتیجه امکان مقایسه را فراهم میکند.
دوره آموزشی متن کاوی با پایتون پیشرفته (مجازی)
همچنین ممکن است بخواهیم بدانیم مردم چه چیزی از بعضی محصولات را مثل گوشیهای هوشمند دوست دارند. لازمه این کار کشف موضوعات در نقد و بررسیهای مثبت و منفی است. یا شاید بخواهیم بدانیم موضوعات اصلی صحبت شده در انتخابات ریاست جمهوری چیست. برای همه این موارد باید کشف و تحلیل موضوعات در متن انجام شود.
چنانچه در شکل 1 نشان داده شده، میتوانیم موضوع را به عنوان چیزی در نظر بگیریم که دانشی درباره جهان را توصیف میکند. میخواهیم از دادههای متنی تعداد از موضوعات را کشف کنیم که میتوانند توصیفی از جهان را فراهم کنند. بر این اساس موضوع چیزی راجع به جهان را به ما میگوید (مثلا راجع به یک محصول یا فرد).
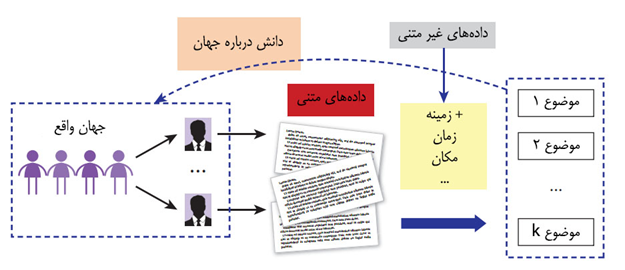
شکل 1 کاوش موضوعات به عنوان دانشی درباره جهان
اغلب در کنار دادههای متنی، دادههای غیر متنی را داریم که میتوانند به عنوان زمینه برای تحلیل موضوعات مورد استفاده قرار بگیرند. ممکن است زمان متناظر با دادههای متنی (یعنی زمان ایجاد) یا مکانهایی که متون در آن ایجاد شده یا مولفین متن یا منابع آن را بدانیم. همه این فرادادهها (یا متغیرهای زمینهای) میتواند با موضوعاتی که کشف میکنیم همراه شده و از آن برای تحلیل الگوهای موضوع بهره ببریم. به عنوان مثال، با مشاهده موضوعات در طول زمان، میتوانیم کشف کنیم که آیا موضوع مورد علاقه یا موضوع در حال محو شدنی وجود دارد. به صورت مشابه، مشاهده موضوعات در مکانهای مختلف میتواند به بینشی راجع به نظرات مردم در مکانهای مختلف منجر شود.
برای دریافت آخرینهای بلاگ و کارگاههای مرکز اطلاعات علمی در خبرنامه عضو شوید.
چنانچه در شکل 2 نشان داده شده است، در وهله نخست، تحلیل موضوع شامل کشف تعداد موضوع میشود. در این نمونه، k موضوع وجود دارد. همچنین میخواهیم بداینم کدام موضوعات در کدام اسناد و به چه میزانی پوشش داده شدهاند. مثلا، این شکل نشان میدهد موضوع 1 در سند 1، به خوبی پوشش داده شده، در حالی که به موضوع 2 و موضوع k پوشش کمی اختصاص یافته است. از سوی دیگر، سند2، موضوع2 را خوب پوشش داده اما موضوع 1 را اصلا پوشش نداده است. این سند مقداری موضوع k را نیز پوشش داده است. بنابراین، در کل دو وظیفه وجود دارد: وظیفه اول کشف k موضوع از مجموعه متنی است؛ وظیفه دوم کشف این است که هر سندی به چه میزان موضوعات را پوشش میدهد.
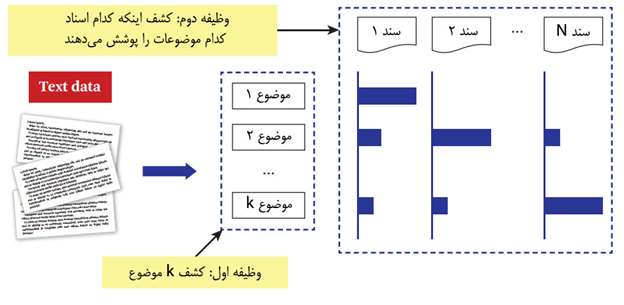
شکل 2 وظیفه کاوش موضوع
به صورت رسمیتر، میتوانیم مسئله را چنانچه در جدول 1 نشان داده شده است تعریف کنیم. به عنوان ورودی مجموعهای از N سند متنی داریم. مجموعه متنی را با C و مقاله را با di مشخص میکنیم. همچنین به عنوان ورودی باید تعداد موضوعات، k، را مشخص کنیم، اگرچه این عدد میتواند به صورت بلقوه بر اساس ویژگیهای دادهها به شکل خودکار تنظیم شود (که ما در اینجا به آن نخواهیم پرداخت).
جدول 1 تعریف رسمی وظایف کاوش موضوع
خروجی شامل k موضوعی است که میخواهیم کشف کنیم، توسط θ1, . . . , θk مشخص شده است، و پوشش موضوعات در هر سند di را نشان میدهد که توسط πij مشخص شده است. πij احتمالی است که سند di موضوع θj را پوشش میدهد. برای هر سند مجموعهای از این مقادیر π داریم که بیان میکنند سند به چه میزان هر موضوع را پوشش داده است. فرض میکنیم مجموع این احتمالات برابر یک باشد، که بر این اساس سند نخواهد توانست موضوعاتی خارج از موضوعات کشف شده را پوشش دهد.
حال، سوال این است که، چگونه موضوع θi را تعریف کنیم؟ تا زمانی که دقیقا θ را تعریف نکنیم، وظیفه ما کامل نشده است. در بخش بعد سادهترین روش تعریف یک موضوع (به عنوان یک اصطلاح) را بحث خواهیم کرد.