جستجوی حریصانه کلمه را با بیشترین احتمال به عنوان کلمه بعدی خود انتخاب می کند:
) wt = argmaxwP (w | w1: t − 1) در هر مرحله t. نمودار زیر جستجوی حریصانه را نشان می دهد.

با شروع از کلمه "The" ، الگوریتم حریصانه کلمه بعدی با بیشترین احتمال "خوب" و غیره را انتخاب می کند ، به طوری که توالی کلمه تولید شده نهایی "The" ، "خوب" ، "زن" است که احتمال کلی 0.5×0.4=0.2
در ادامه توالی کلمات با استفاده از GPT2 در زمینه ("I", "enjoy", "walking", "with", "my", "cute", "dog" (ایجاد خواهیم کرد.


اولین متن کوتاه خود را با GPT2 تولید کرده ایم. کلمات تولید شده پیرو متن منطقی هستند، اما مدل به سرعت شروع به تکرار می کند! به طور کلی این یک مسئله بسیار شایع در تولید زبان است و به نظر می رسد در جستجوی حریص و پرتو حتی بیشتر است.
برای دریافت آخرینهای بلاگ و کارگاههای مرکز اطلاعات علمی در خبرنامه عضو شوید.
اشکال عمده جستجوی حریصانه این است که کلمات با احتمال زیاد پنهان شده در پشت یک کلمه احتمال کم را از دست می دهد همانطور که در طرح بالا مشاهده می شود:
کلمه "has" با احتمال زیاد شرطی آن 0.9 در پشت کلمه "dog" پنهان شده است ، که تنها دومین احتمال شرطی بالاترین را دارد ، بنابراین جستجوی حریصانه کلمه دنباله کلمه "The" ، "dog" ، "has" را از دست می دهد .
برای رفع این مسئله از جتجوی پرتو استفاده می کنیم.
Beam search
جستجوی پرتو با حفظ محتمل ترین تعداد فرضیه در هر مرحله و در نهایت انتخاب فرضیه ای که بالاترین احتمال را دارد ، خطر از دست رفتن توالی کلمات با احتمال زیاد پنهان را کاهش می دهد. num_beams = 2 تصویر کنیم:
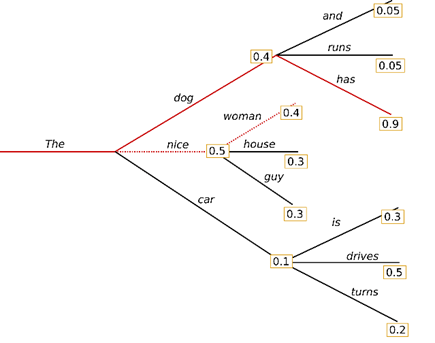
در مرحله اول ، علاوه بر محتمل ترین فرضیه "woman" ، "The" ، جستجوی پرتو همچنین دومین فرضیه "dog" به احتمال زیاد را دنبال می کند. در مرحله 2 ، جستجوی پرتو دریافت که دنباله کلمه "The" ، "Dog" ، "has" با 0.36 احتمال بیشتری نسبت به "The" ، "nice" ، "woman" دارد که دارای 0.2 است.جستجوی پرتو همیشه یک توالی خروجی با احتمال بالاتر از جستجوی حریصانه پیدا می کند ، اما تضمین نمی کند که محتمل ترین نتیجه را پیدا کند.
شروع پایتون در anaconda
می توان از جستجوی پرتو در ترانسفورماتورها استفاده کرد. num_beams> 1 و early_stopping = True را تنظیم می کنیم تا وقتی تمام فرضیه های پرتو به رمز EOS رسید ، تولید به پایان برسد.
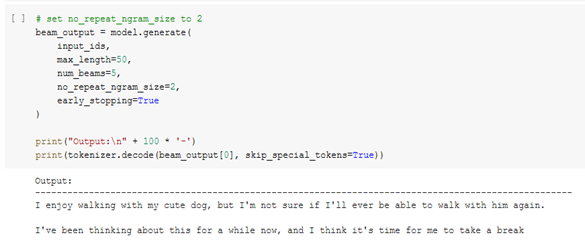
بازهم تکرارهای توالی کلمات یکسان است.
یک راه حل ساده n-گرم (توالی کلمه n کلمات) است که توسط Paulus و همکاران معرفی شده است. (2017) و کلاین و همکاران (2017) رایج ترین مجازات [1]n-gram با تعیین دستی کلمات بعدی که می توانند n-گرم قبلاً دیده شده را روی 0 ایجاد کنند ، اطمینان حاصل می کند که هیچ n-gram دو بار ظاهر نمی شود.
با تنظیم no_repeat_ngram_size = 2 آن را امتحان کنیم تا هیچ 2-gram دو بار ظاهر نشود:
اخیراً چند دلیل ارائه شده است که چرا جستجوی پرتو بهترین گزینه ممکن نیست:
- جستجوی پرتو می تواند در کارهایی که طول نسل مورد نظر کم و بیش قابل پیش بینی است مانند ترجمه یا خلاصه سازی ماشینی بسیار خوب کار کند - به موری و همکاران مراجعه کنید. (2018) و یانگ و همکاران (2018)
- جستجوی پرتو به شدت از تولید تکراری رنج می برد. کنترل این امر به ویژه با استفاده از n گرم یاpenalties های دیگر در تولید متن بسیار دشوار است ، زیرا یافتن یک معامله خوب بین "بدون تکرار" اجباری و تکرار چرخه های n-گرم یکسان نیاز به ریزکاری زیادی دارد.
- همانطور که در آری هولتزمن [2]و همکاران بحث شد. (2019) ، زبان انسانی با کیفیت بالا توزیع احتمالات بالا را در کلمات بعدی دنبال نمی کند. به عبارت دیگر ، ما به عنوان انسان ، می خواهیم متن تولید شده ما را غافلگیر کند و خسته کننده / قابل پیش بینی نباشد. نویسندگان با طرح این احتمال ، مدلی را به متن انسان در مقابل آنچه جستجوی پرتو انجام می دهد ، به خوبی نشان می دهند.

Sampling
در ابتدایی ترین شکل ، نمونه گیری به معنای انتخاب تصادفی کلمه بعدی wt با توجه به توزیع احتمال شرطی آن است:
(wt∼P (w | w1: t – 1)
نمودار زیر language generationرا هنگام نمونه برداری تجسم می کند.

آشکار می شود که تولید زبان با استفاده از نمونه گیری دیگر قطعی نیست. کلمه "اتومبیل" از توزیع احتمال شرطی
P (w | "The")
نمونه برداری می شود و به دنبال نمونه
"drive" از P(w|"The","car")
در ترانسفورماتورها ، do_sample = True را انتخاب کرده و نمونه برداری Top-K را غیرفعال می کنیم از طریق top_k = 0. در زیر ، random_seed = 0 را برای اهداف تصویرسازی اصلاح خواهیم کرد. می توانید seed_seed را تغییر دهید.

متن خوب به نظر می رسد - اما هنگام بررسی دقیق ، چندان منسجم نیست. دسته سه گرمی جدید دست و مهار بته محلی بسیار عجیب است و به نظر نمی رسد که توسط انسان نوشته شده باشد. این مسئله بزرگ در هنگام نمونه برداری از توالی کلمات است: مدلها غالباً ناخوشایند تولید می کنند.
هشتمین کارگاه آموزشی یادگیری عمیق (deep learning) (مجازی)
یک ترفند این است که توزیع P (w | w1: t-1) را واضح ترکنید (با افزایش احتمال کلمات با احتمال زیاد و کاهش احتمال کلمات با احتمال کم) با کاهش دمای به اصطلاح softmax.
تصویری از کاربرد temperature در مثال ما از بالا می تواند به صورت زیر باشد.

توزیع کلمه بعدی شرطی مرحله t = 1 بسیار واضح تر می شود و تقریباً فرصتی برای انتخاب کلمه "ماشین" ایجاد نمی شود.